


¿Alguna vez miras las noticias y te preguntas sobre el proceso detrás del ciclo de noticias? Lo hice, y durante las últimas dos décadas ha sido objeto de uno de mis proyectos. La frambuesa Pi en mi estante corre Mi herramienta de análisis de tendencias de palabras para contenido de noticiasy desde mi viaje de Curious Geek a tener mi propio sistema de análisis de grandes corpus ha tomado veinte años, vale la pena un segundo vistazo.
Cómo la agitación profesional condujo a un proyecto de dos décadas

A mediados de la década de 2000 había salido del bloqueo de Dotcom en su mayoría intacto, y estaba trabajando para una pequeña tienda internet. Cuando fueron a la quiebra, estaba lanzando como uno, y pasé un tiempo como Un evaluador de calidad de Google Mientras buscaba un nuevo trabajo de permie. Estos equipos son empleados por el gigante de la búsqueda a través de agencias de empleo temporales, y en términos flojos, su trabajo es ser los monos capacitados contra los cuales se prueba el algoritmo. El algoritmo eligió X, y si los humanos también eligieron X, el algoritmo probablemente lo está haciendo bien. Ser un evaluador de calidad no es de ninguna manera un trabajo de alto perfil, pero con el gran G brillante en mi CV, pronto me encontré en demanda de las compañías internet que buscan una experiencia de advertising and marketing de motores de búsqueda de sombrero blanco. Lo que aprendí reflejó mi lección de una década antes en el negocio de CD-ROM, que en la internet como en cualquier otro medio de publicación electrónica, buen contenido bien presentado tiene prioridad sobre cualquier truco de sombrero negro.
Pero, ¿qué hace un buen contenido? Olvídese de una obsesión por rellenar palabras clave falsas en el texto y, en su lugar, hablar sobre las cosas correctas, y hacerlo con autoridad. ¿Cuáles son las cosas correctas en este contexto? Si está cubriendo un tema, debe hacerlo usando el lenguaje correcto; lo que usa la mayoría en lugar del lenguaje solo usted usa. Puedo pensar en un montón de ejemplos de los que probablemente no debería hablar, pero un ejemplo cercano a casa para mí viene en la sidra. En el Reino Unido, la sidra es una bebida alcohólica fermentada hecha de manzanas, y como un cidermaker artesanal de muchos años de pie tengo una buena comprensión de su vocabulario. La ortografía aceptada es “sidra”, pero hay una ortografía alternativa de “Cyder” utilizada por algunos productores comerciales de la bebida. No lleva mucho tiempo darse cuenta de que en línea, casi nadie usa Cyder con una Y y, por lo tanto, las páginas concentrarse en esa palabra funcionarán menos que aquellos que hablan de sidra.
Comencé a construir software program para analizar el lenguaje en torno a un tema determinado, con el objetivo de discernir la sidra metafórica del Cyder. Fue una gran sorpresa unos años más tarde descubrir que me había inventado el campo ya existente de lingüística computacional, algo que me hubiera ahorrado mucho tiempo si lo hubiera sabido cuando comencé. Estaba tomando un corpus de texto y calculando las frecuencias y colocados (palabras que aparecen una vez al otro) de las palabras dentro de él, y de eso podía ver rápidamente qué redacción importaba alrededor de un sujeto, y cuál no. Esto llevó a la perfección a un interés en cómo se vería el mismo proceso para los datos de noticias con un eje de tiempo agregado, por lo que creé una versión que cosechó su corpus de RSS Feeds. Así comenzó mi proyecto de décadas.
Desde la concept del proyecto, hasta Corpus Equipment
En 2005 sabía cómo crear sitios internet a la manera del día, así que utilicé las herramientas que tenía. PHP5 y MySQL. Sé que PHP no está de moda en estos días, pero en ese momento esto no period demasiado controvertido, y aparte de todo el código PHP de calidad cuestionable, sigue siendo un lenguaje de secuencias de comandos útil. Sin embargo, usar MySQL me causaría inmensos problemas. Había hecho lo que parecía lo correcto y creé una base de datos estructurada con tablas vinculadas, pero no había apreciado completamente cuán enorme period la tarea que había asumido. La cosecha de la manguera de fuego RSS en múltiples medios de comunicación trae miles de historias cada semana, por lo que las consultas que fueron casi instantáneas durante mis primeras etapas de desarrollo crecieron hasta tomar muchos minutos a medida que mi corpus se expandió. Period hora de encontrar una alternativa, y la encontré en las características más básicas del sistema operativo, el sistema de archivos.
Volviendo a la década de 1990, cuando pagó por el alojamiento internet, se dio en términos del espacio de almacenamiento con el que vino. No se consideró la potencia de procesamiento requerida para ejecutar sus scripts CGI o intérpretes posteriores del lado del servidor como ASP o PHP. Por lo tanto, se convirtió en una práctica regular tratar de reducir el uso de almacenamiento y no pensar en el procesamiento, y no pensé en este camino.
Pero para la década de 2000, el precio del almacenamiento había caído enormemente mientras que el procesamiento no lo había hecho. Esta fue la década en la que los servicios en la nube como AWS aparecieron, y además de comprar discos duros de muchos gigabytes por no mucho, también podría alquilar un cubo de nubes para centavos. Mi sistema de análisis de corpus no necesitaba pasar todo su tiempo calculando si pudiera usar un disco duro de terabyte para compensar menos uso del procesador, así que volví mi sistema en la cabeza. Al recopilar las historias de RSS, mi script de recuperación precomputaría los datos finales y los almacenaría en un vasto árbol de pequeños archivos JSON accesibles a alta velocidad a través del sistema de archivos, y luego mi software program de análisis podría simplemente recuperarlos y hacer su informe. El sistema pasó de una computadora portátil X86 trabajadora a una frambuesa Pi de susurque y de baja potencia con un disco duro USB, y allí se ha quedado de alguna forma desde entonces.
¿Qué puede hacer esto?
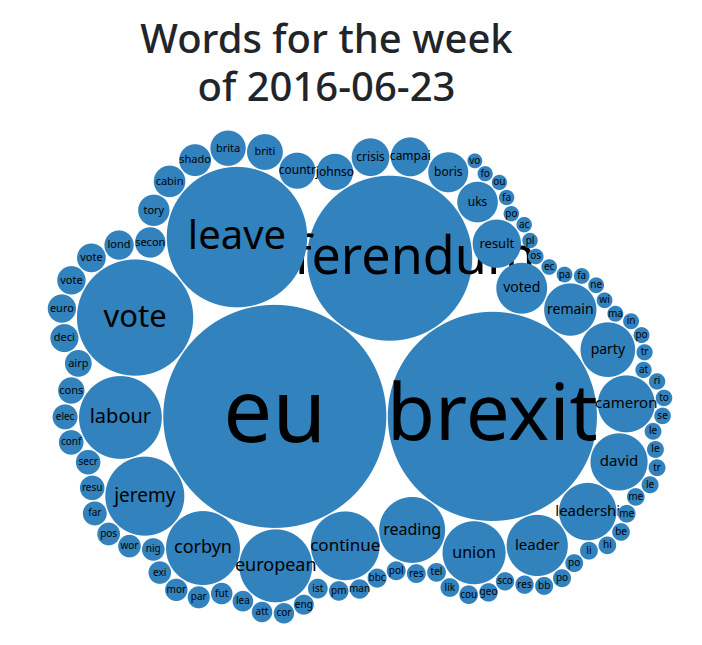
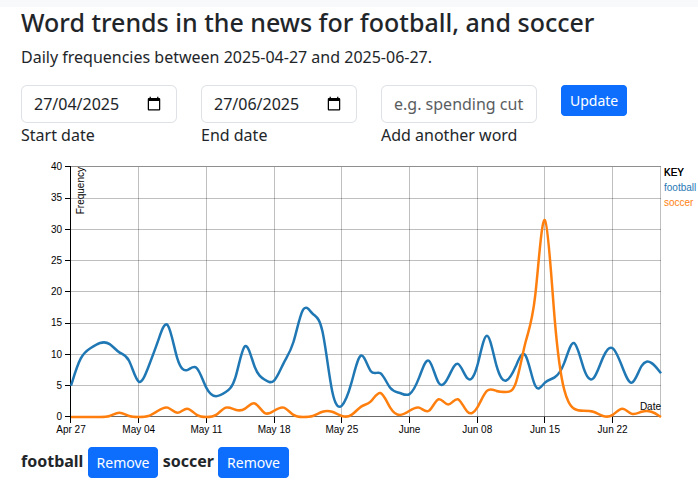
Así que tengo un corpus de noticias que me ha llevado mucho tiempo construir. Puedo tomar una o más palabras, y puedo comparar su ocurrencia con el tiempo. Puedo ver el ciclo de noticias, puedo ver historias acumuladas con el tiempo. Incluso puedo ver tendencias que a veces van en contra de la opinión recibida, como detectar esa Es probable que el eventual ganador de la carrera de liderazgo laborista del Reino Unido 2016 fuera Jeremy Corbyn Al principio, mientras el rebaño miraba en otro lado. A veces, al igual que con el rendimiento de la palabra “Brexit” a mediados de la última década, puedo ver los grandes eventos de nuestros tiempos en alivio, pero tal vez no sea obvio que haya más valor. Si sigues un tema y de repente se seca durante un par de días, espere una historia realmente grande el tercer día, por ejemplo. También puedo ver qué puntos de venta cubren una historia más que otra, algo útil al tratar de determinar si se está empujando un tema en nombre de un foyer en specific.
Mi experimento en el análisis de texto luego se convirtió en algo mucho más, incluso me atrevo a decirlo, algo que encuentro de ayuda para descubrir lo que realmente está sucediendo en tiempos turbulentos. Pero desde un punto de vista tecnológico, me ha enseñado una gran cantidad, sobre las estadísticas, sobre el lenguaje, sobre el análisis de texto e incluso sobre ver la cantidad de inodos disponibles en un disco duro. Créeme, muchos millones de archivos pequeños en un árbol pueden volverse difíciles de manejar. Pero quizás sobre todo, después de una vida de irrumpir con todo tipo de proyectos, pero generando poco de importancia duradera, puedo ver este y decir que creé algo. útil. Y eso es algo de lo que estar feliz.













{kind=link}