


Descripción normal del contenido
- Introducción
- Descripción normal de los optimizadores
- Configuración
- Descenso de gradiente
- Descenso de gradiente con impulso
- Estimación de momento adaptativo (Adam)
- Conclusión
Introducción
El módulo Keras Optimizers es el conjunto de herramientas de optimización recomendado para muchos fines de capacitación normal. Incluye una variedad de optimizadores preconstruidos, así como la funcionalidad de subclasificación para la personalización. Los optimizadores de Keras también son compatibles con capas personalizadas, modelos y bucles de entrenamiento construidos con las API básicas. Estos optimizadores prebujados y personalizables son adecuados para la mayoría de los casos, pero las API básicas permiten un management completo sobre el proceso de optimización. Por ejemplo, las técnicas como la minimización de nitidez (SAM) requieren que el modelo y el optimizador se acoplen, lo que no se ajusta a la definición tradicional de optimizadores de ML. Esta guía pasa por el proceso de construcción de optimizadores personalizados desde cero con las API básicas, lo que le brinda el poder de tener un management whole sobre la estructura, la implementación y el comportamiento de sus optimizadores.
Descripción normal de los optimizadores
Un optimizador es un algoritmo utilizado para minimizar una función de pérdida con respecto a los parámetros capacitables de un modelo. La técnica de optimización más directa es el descenso de gradiente, que actualiza iterativamente los parámetros de un modelo dando un paso en la dirección del descenso más empinado de su función de pérdida. Su tamaño de paso es directamente proporcional al tamaño del gradiente, lo que puede ser problemático cuando el gradiente es demasiado grande o demasiado pequeño. Hay muchos otros optimizadores basados en gradientes como Adam, Adagrad y RMSProp que aprovechan varias propiedades matemáticas de los gradientes para la eficiencia de la memoria y la convergencia rápida.
Configuración
import matplotlib
from matplotlib import pyplot as plt
# Preset Matplotlib determine sizes.
matplotlib.rcParams['figure.figsize'] = [9, 6]
import tensorflow as tf
print(tf.__version__)
# set random seed for reproducible outcomes
tf.random.set_seed(22)
2024-08-15 02:37:52.102563: E exterior/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT manufacturing facility: Making an attempt to register manufacturing facility for plugin cuFFT when one has already been registered
2024-08-15 02:37:52.123704: E exterior/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN manufacturing facility: Making an attempt to register manufacturing facility for plugin cuDNN when one has already been registered
2024-08-15 02:37:52.130222: E exterior/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS manufacturing facility: Making an attempt to register manufacturing facility for plugin cuBLAS when one has already been registered
2.17.0
Descenso de gradiente
La clase Fundamental Optimizer debe tener un método de inicialización y una función para actualizar una lista de variables dada una lista de gradientes. Comience por implementar el optimizador de descenso de gradiente básico que actualiza cada variable restando su gradiente escalado por una tasa de aprendizaje.
class GradientDescent(tf.Module):
def __init__(self, learning_rate=1e-3):
# Initialize parameters
self.learning_rate = learning_rate
self.title = f"Gradient descent optimizer: studying price={self.learning_rate}"
def apply_gradients(self, grads, vars):
# Replace variables
for grad, var in zip(grads, vars):
var.assign_sub(self.learning_rate*grad)
Para probar este optimizador, cree una función de pérdida de muestra para minimizar con respecto a una sola variable, x. Calcule su función de gradiente y resuelva para su valor de parámetro de minimización:
L = 2×4+3×3+2
dldx = 8×3+9×2
DLDX es 0 en x = 0, que es un punto de silla de montar y en x = −98, que es el mínimo international. Por lo tanto, la función de pérdida se optimiza en x⋆ = −98.
x_vals = tf.linspace(-2, 2, 201)
x_vals = tf.forged(x_vals, tf.float32)
def loss(x):
return 2*(x**4) + 3*(x**3) + 2
def grad(f, x):
with tf.GradientTape() as tape:
tape.watch(x)
outcome = f(x)
return tape.gradient(outcome, x)
plt.plot(x_vals, loss(x_vals), c='okay', label = "Loss operate")
plt.plot(x_vals, grad(loss, x_vals), c='tab:blue', label = "Gradient operate")
plt.plot(0, loss(0), marker="o", c='g', label = "Inflection level")
plt.plot(-9/8, loss(-9/8), marker="o", c='r', label = "World minimal")
plt.legend()
plt.ylim(0,5)
plt.xlabel("x")
plt.ylabel("loss")
plt.title("Pattern loss operate and gradient");
WARNING: All log messages earlier than absl::InitializeLog() is named are written to STDERR
I0000 00:00:1723689474.551312 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.555159 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.558916 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.562138 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.573919 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.577367 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.580786 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.583786 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.587331 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.590801 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.594185 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689474.597140 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.839513 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.841532 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.844269 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.846345 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.848395 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.850251 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.852146 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.854142 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.856078 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.857966 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.859861 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.861827 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.899762 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.901715 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.903659 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.905680 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.907718 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.909592 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.911505 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.913511 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.915419 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.917727 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.919991 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at
I0000 00:00:1723689475.922410 124187 cuda_executor.cc:1015] profitable NUMA node learn from SysFS had unfavourable worth (-1), however there should be at the least one NUMA node, so returning NUMA node zero. See extra at

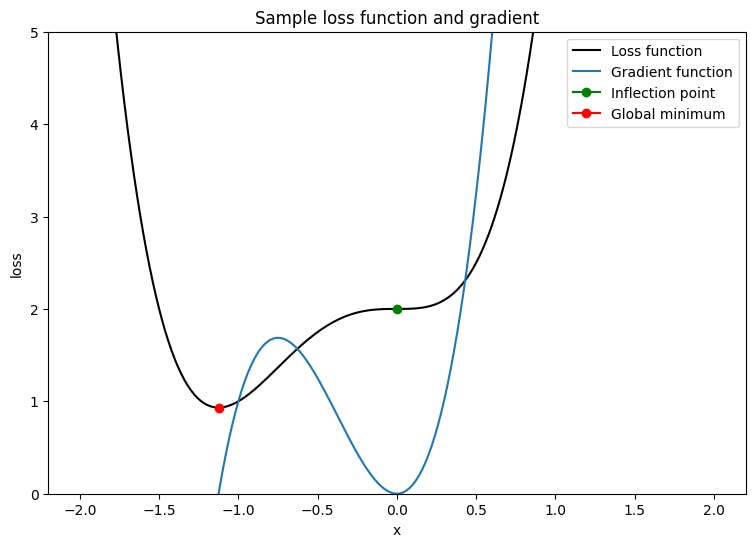
Escriba una función para probar la convergencia de un optimizador con una sola función de pérdida de variable. Suponga que la convergencia se ha logrado cuando el valor del parámetro actualizado en TimeStep t es el mismo que su valor mantenido en TimeStep t – 1. Termine la prueba después de un número establecido de iteraciones y también realice un seguimiento de los gradientes de explosión durante el proceso. Para desafiar realmente el algoritmo de optimización, inicialice mal el parámetro. En el ejemplo anterior, x = 2 es una buena opción ya que involucra un gradiente empinado y también conduce a un punto de inflexión.
def convergence_test(optimizer, loss_fn, grad_fn=grad, init_val=2., max_iters=2000):
# Perform for optimizer convergence take a look at
print(optimizer.title)
print("-------------------------------")
# Initializing variables and constructions
x_star = tf.Variable(init_val)
param_path = []
converged = False
for iter in vary(1, max_iters + 1):
x_grad = grad_fn(loss_fn, x_star)
# Case for exploding gradient
if tf.math.is_nan(x_grad):
print(f"Gradient exploded at iteration {iter}n")
return []
# Updating the variable and storing its old-version
x_old = x_star.numpy()
optimizer.apply_gradients([x_grad], [x_star])
param_path.append(x_star.numpy())
# Checking for convergence
if x_star == x_old:
print(f"Converged in {iter} iterationsn")
converged = True
break
# Print early termination message
if not converged:
print(f"Exceeded most of {max_iters} iterations. Check terminated.n")
return param_path
Pruebe la convergencia del optimizador de descenso de gradiente para las siguientes tarifas de aprendizaje: 1e-3, 1e-2, 1e-1
param_map_gd = {}
learning_rates = [1e-3, 1e-2, 1e-1]
for learning_rate in learning_rates:
param_map_gd[learning_rate] = (convergence_test(
GradientDescent(learning_rate=learning_rate), loss_fn=loss))
Gradient descent optimizer: studying price=0.001
-------------------------------
Exceeded most of 2000 iterations. Check terminated.
Gradient descent optimizer: studying price=0.01
-------------------------------
Exceeded most of 2000 iterations. Check terminated.
Gradient descent optimizer: studying price=0.1
-------------------------------
Gradient exploded at iteration 6
Visualice la ruta de los parámetros sobre una gráfica de contorno de la función de pérdida.
def viz_paths(param_map, x_vals, loss_fn, title, max_iters=2000):
# Making a controur plot of the loss operate
t_vals = tf.vary(1., max_iters + 100.)
t_grid, x_grid = tf.meshgrid(t_vals, x_vals)
loss_grid = tf.math.log(loss_fn(x_grid))
plt.pcolormesh(t_vals, x_vals, loss_grid, vmin=0, shading='nearest')
colours = ['r', 'w', 'c']
# Plotting the parameter paths over the contour plot
for i, learning_rate in enumerate(param_map):
param_path = param_map[learning_rate]
if len(param_path) > 0:
x_star = param_path[-1]
plt.plot(t_vals[:len(param_path)], param_path, c=colours[i])
plt.plot(len(param_path), x_star, marker='o', c=colours[i],
label = f"x*: studying price={learning_rate}")
plt.xlabel("Iterations")
plt.ylabel("Parameter worth")
plt.legend()
plt.title(f"{title} parameter paths")
viz_paths(param_map_gd, x_vals, loss, "Gradient descent")
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/IPython/core/occasions.py:82: UserWarning: Creating legend with loc="greatest" will be sluggish with massive quantities of knowledge.
func(*args, **kwargs)


El descenso de gradiente parece atascarse en el punto de inflexión cuando se usa tasas de aprendizaje más pequeñas. Aumentar la tasa de aprendizaje puede fomentar un movimiento más rápido alrededor de la región de la meseta debido a un tamaño de paso más grande; Sin embargo, esto corre en riesgo de tener gradientes explosivos en las primeras iteraciones cuando la función de pérdida es extremadamente empinada.
Descenso de gradiente con impulso
El descenso de gradiente con impulso no solo usa el gradiente para actualizar una variable, sino que también implica el cambio en la posición de una variable basada en su actualización anterior. El parámetro de impulso determina el nivel de influencia que la actualización en TimeStep T – 1 tiene en la actualización en TimeStep t. La acumulación de impulso ayuda a mover las variables más allá de las regiones de Plataeu más rápido que el descenso de gradiente básico. La regla de actualización de impulso es la siguiente:
Δx[t]= lr previous ′ (x[t−1])+p⋅δx[t−1]
incógnita[t]= x[t−1]−Δx[t]
dónde
- X: la variable que se optimiza
- Δx: cambio en x
- LR: tasa de aprendizaje
- L ′ (x): gradiente de la función de pérdida con respecto a x
- P: parámetro de momento
class Momentum(tf.Module):
def __init__(self, learning_rate=1e-3, momentum=0.7):
# Initialize parameters
self.learning_rate = learning_rate
self.momentum = momentum
self.change = 0.
self.title = f"Gradient descent optimizer: studying price={self.learning_rate}"
def apply_gradients(self, grads, vars):
# Replace variables
for grad, var in zip(grads, vars):
curr_change = self.learning_rate*grad + self.momentum*self.change
var.assign_sub(curr_change)
self.change = curr_change
Pruebe la convergencia del optimizador de impulso para las siguientes tasas de aprendizaje: 1e-3, 1e-2, 1e-1
param_map_mtm = {}
learning_rates = [1e-3, 1e-2, 1e-1]
for learning_rate in learning_rates:
param_map_mtm[learning_rate] = (convergence_test(
Momentum(learning_rate=learning_rate),
loss_fn=loss, grad_fn=grad))
Gradient descent optimizer: studying price=0.001
-------------------------------
Exceeded most of 2000 iterations. Check terminated.
Gradient descent optimizer: studying price=0.01
-------------------------------
Converged in 80 iterations
Gradient descent optimizer: studying price=0.1
-------------------------------
Gradient exploded at iteration 6
Visualice la ruta de los parámetros sobre una gráfica de contorno de la función de pérdida.
viz_paths(param_map_mtm, x_vals, loss, "Momentum")

Estimación de momento adaptativo (Adam)
El algoritmo de estimación de momento adaptativo (ADAM) es una técnica de optimización eficiente y altamente generalizable que aprovecha dos metedologías de descenso de gradiente clave: impulso y propagación cuadrada media de raíz (RMSP). El momento ayuda a acelerar el descenso de gradiente utilizando el primer momento (suma de gradientes) junto con un parámetro de descomposición. RMSP es related; Sin embargo, aprovecha el segundo momento (suma de gradientes al cuadrado).
El algoritmo Adam combina el primer y segundo momento para proporcionar una regla de actualización más generalizable. El signo de una variable, x, se puede determinar calculando xx2. Adam Optimizer utiliza este hecho para calcular un paso de actualización que es efectivamente un signo suavizado. En lugar de calcular XX2, el optimizador calcula una versión suavizada de X (primer momento) y X2 (segundo momento) para cada actualización de variable.
Algoritmo de Adam
β1 ← 0.9▹ Valor de literatura
β2 ← 0.999▹ Valor de literatura
LR ← 1E-3▹ Tasa de aprendizaje configurable
ϵ ← 1e-7▹ Los especificaciones dividen por 0 error
VDV ← 0N × 1 → ▹ Actualizaciones de impulso de almacenamiento para cada variable
SDV ← 0N × 1 → ▹ Las actualizaciones RMSP de almacenamiento para cada variable
t ← 1
En iteración t:
Para (DLDV, V) en pares de variables de gradiente:
VDV_I = β1VDV_I+(1 – β1) Actualización de dldv▹Momentum
SDV_I = β2VDV_I+(1 – β2) (DLDV) 2▹RMSP Actualización
VDVBC = VDV_I (1 – β1) Corrección de sesgo T▹Momentum
SDVBC = SDV_I (1 – β2) Corrección de polarización T▹RMSP
V = V – LRVDVBCSDVBC+ϵ▹Parameter actualización
t = t+1
Fin del algoritmo
Dado que VDV y SDV se inicializan a 0 y que β1 y β2 están cerca de 1, las actualizaciones de Momentum y RMSP están sesgadas naturalmente hacia 0; Por lo tanto, las variables pueden beneficiarse de la corrección de sesgo. La corrección de sesgo también ayuda a controlar la oscilación de los pesos a medida que se acercan al mínimo international.
class Adam(tf.Module):
def __init__(self, learning_rate=1e-3, beta_1=0.9, beta_2=0.999, ep=1e-7):
# Initialize the Adam parameters
self.beta_1 = beta_1
self.beta_2 = beta_2
self.learning_rate = learning_rate
self.ep = ep
self.t = 1.
self.v_dvar, self.s_dvar = [], []
self.title = f"Adam: studying price={self.learning_rate}"
self.constructed = False
def apply_gradients(self, grads, vars):
# Arrange second and RMSprop slots for every variable on the primary name
if not self.constructed:
for var in vars:
v = tf.Variable(tf.zeros(form=var.form))
s = tf.Variable(tf.zeros(form=var.form))
self.v_dvar.append(v)
self.s_dvar.append(s)
self.constructed = True
# Carry out Adam updates
for i, (d_var, var) in enumerate(zip(grads, vars)):
# Second calculation
self.v_dvar[i] = self.beta_1*self.v_dvar[i] + (1-self.beta_1)*d_var
# RMSprop calculation
self.s_dvar[i] = self.beta_2*self.s_dvar[i] + (1-self.beta_2)*tf.sq.(d_var)
# Bias correction
v_dvar_bc = self.v_dvar[i]/(1-(self.beta_1**self.t))
s_dvar_bc = self.s_dvar[i]/(1-(self.beta_2**self.t))
# Replace mannequin variables
var.assign_sub(self.learning_rate*(v_dvar_bc/(tf.sqrt(s_dvar_bc) + self.ep)))
# Increment the iteration counter
self.t += 1.
Pruebe el rendimiento del ADAM Optimizer con las mismas tasas de aprendizaje utilizadas con los ejemplos de descenso de gradiente.
param_map_adam = {}
learning_rates = [1e-3, 1e-2, 1e-1]
for learning_rate in learning_rates:
param_map_adam[learning_rate] = (convergence_test(
Adam(learning_rate=learning_rate), loss_fn=loss))
Adam: studying price=0.001
-------------------------------
Exceeded most of 2000 iterations. Check terminated.
Adam: studying price=0.01
-------------------------------
Exceeded most of 2000 iterations. Check terminated.
Adam: studying price=0.1
-------------------------------
Converged in 1156 iterations
Visualice la ruta de los parámetros sobre una gráfica de contorno de la función de pérdida.
viz_paths(param_map_adam, x_vals, loss, "Adam")

En este ejemplo explicit, el ADAM Optimizer tiene una convergencia más lenta en comparación con el descenso de gradiente tradicional cuando se usa pequeñas tasas de aprendizaje. Sin embargo, el algoritmo pasa con éxito más allá de la región de Plataeu y converge al mínimo international cuando una tasa de aprendizaje mayor. Los gradientes explosivos ya no son un problema debido a la escala dinámica de Adam de las tasas de aprendizaje al encontrar grandes gradientes.
Conclusión
Este cuaderno introdujo los conceptos básicos de la escritura y la comparación de optimizadores con las API del núcleo TensorFlow. Aunque los optimizadores previos a la construcción como Adam son generalizables, es posible que no siempre sean la mejor opción para cada modelo o conjunto de datos. Tener un management de grano fino sobre el proceso de optimización puede ayudar a optimizar los flujos de trabajo de capacitación de ML y mejorar el rendimiento normal. Consulte la siguiente documentación para obtener más ejemplos de optimizadores personalizados:
Publicado originalmente en el

")










")
{kind=link}