


Descripción normal del contenido
- Configuración
- Guardar de las API de entrenamiento de TF.Keras
- Escribir puntos de management
- Punta de management handbook
- Mecánica de carga
- Restauraciones diferidas
- Inspeccionar manualmente los puntos de management
- Seguimiento de objetos
- Resumen
La frase “Guardar un modelo TensorFlow” generalmente significa una de dos cosas:
- Puntos de management, o
- SavedModel.
Los puntos de management capturan el valor exacto de todos los parámetros (tf.Variable objetos) utilizado por un modelo. Los puntos de management no contienen ninguna descripción del cálculo definido por el modelo y, por lo tanto, generalmente son útiles cuando el código fuente que usará los valores de parámetros guardados está disponible.
El formato SavedModel, por otro lado, incluye una descripción serializada del cálculo definido por el modelo además de los valores de parámetros (punto de management). Los modelos en este formato son independientes del código fuente que creó el modelo. Por lo tanto, son adecuados para la implementación a través de TensorFlow Serving, Tensorflow Lite, TensorFlow.js o programas en otros lenguajes de programación (C, C ++, Java, GO, Rust, C# and so on. API de flujo de tensor).
Esta guía cubre API para escribir y leer puntos de management.
Configuración
import tensorflow as tf
class Web(tf.keras.Mannequin):
"""A easy linear mannequin."""
def __init__(self):
tremendous(Web, self).__init__()
self.l1 = tf.keras.layers.Dense(5)
def name(self, x):
return self.l1(x)
internet = Web()
Ahorrando desde tf.keras API de entrenamiento
Ver el tf.keras Guía sobre salvar y restaurar.
tf.keras.Mannequin.save_weights Guarda un punto de management TensorFlow.
internet.save_weights('easy_checkpoint')
Escribir puntos de management
El estado persistente de un modelo de flujo tensor se almacena en tf.Variable objetos. Estos se pueden construir directamente, pero a menudo se crean a través de API de alto nivel como tf.keras.layers o tf.keras.Mannequin.
La forma más fácil de administrar las variables es unirlas a los objetos de Python y luego hacer referencia a esos objetos.
Subclases de tf.practice.Checkpoint, tf.keras.layers.Layery tf.keras.Mannequin Rastree automáticamente las variables asignadas a sus atributos. El siguiente ejemplo construye un modelo lineal easy, luego escribe puntos de management que contienen valores para todas las variables del modelo.
Puede guardar fácilmente un modelo de modelo con Mannequin.save_weights.
Punta de management handbook
Configuración
Para ayudar a demostrar todas las características de tf.practice.CheckpointDefina un conjunto de datos de juguete y un paso de optimización:
def toy_dataset():
inputs = tf.vary(10.)[:, None]
labels = inputs * 5. + tf.vary(5.)[None, :]
return tf.information.Dataset.from_tensor_slices(
dict(x=inputs, y=labels)).repeat().batch(2)
def train_step(internet, instance, optimizer):
"""Trains `internet` on `instance` utilizing `optimizer`."""
with tf.GradientTape() as tape:
output = internet(instance['x'])
loss = tf.reduce_mean(tf.abs(output - instance['y']))
variables = internet.trainable_variables
gradients = tape.gradient(loss, variables)
optimizer.apply_gradients(zip(gradients, variables))
return loss
Crea los objetos de punto de management
Usar un tf.practice.Checkpoint Objeto para crear manualmente un punto de management, donde los objetos que desea ver se establecen como atributos en el objeto.
A tf.practice.CheckpointManager También puede ser útil para administrar múltiples puntos de management.
choose = tf.keras.optimizers.Adam(0.1)
dataset = toy_dataset()
iterator = iter(dataset)
ckpt = tf.practice.Checkpoint(step=tf.Variable(1), optimizer=choose, internet=internet, iterator=iterator)
supervisor = tf.practice.CheckpointManager(ckpt, './tf_ckpts', max_to_keep=3)
Entrena y punto de management del modelo
El siguiente bucle de entrenamiento crea una instancia del modelo y de un optimizador, luego los reúne en un tf.practice.Checkpoint objeto. Llama al paso de entrenamiento en un bucle en cada lote de datos, y escribe periódicamente los puntos de management en el disco.
def train_and_checkpoint(internet, supervisor):
ckpt.restore(supervisor.latest_checkpoint)
if supervisor.latest_checkpoint:
print("Restored from {}".format(supervisor.latest_checkpoint))
else:
print("Initializing from scratch.")
for _ in vary(50):
instance = subsequent(iterator)
loss = train_step(internet, instance, choose)
ckpt.step.assign_add(1)
if int(ckpt.step) % 10 == 0:
save_path = supervisor.save()
print("Saved checkpoint for step {}: {}".format(int(ckpt.step), save_path))
print("loss {:1.2f}".format(loss.numpy()))
train_and_checkpoint(internet, supervisor)
Restaurar y continuar entrenando
Después del primer ciclo de entrenamiento, puede aprobar un nuevo modelo y gerente, pero recoger la capacitación exactamente donde lo dejó:
choose = tf.keras.optimizers.Adam(0.1)
internet = Web()
dataset = toy_dataset()
iterator = iter(dataset)
ckpt = tf.practice.Checkpoint(step=tf.Variable(1), optimizer=choose, internet=internet, iterator=iterator)
supervisor = tf.practice.CheckpointManager(ckpt, './tf_ckpts', max_to_keep=3)
train_and_checkpoint(internet, supervisor)
El tf.practice.CheckpointManager El objeto elimina los viejos puntos de management. Arriba está configurado para mantener solo los tres puntos de management más recientes.
print(supervisor.checkpoints) # Checklist the three remaining checkpoints
Estos caminos, por ejemplo './tf_ckpts/ckpt-10'no son archivos en el disco. En su lugar, son prefijos para un index Archivo y uno o más archivos de datos que contienen los valores variables. Estos prefijos se agrupan en un solo checkpoint archivo ('./tf_ckpts/checkpoint') donde el CheckpointManager salva su estado.
ls ./tf_ckpts
Mecánica de carga
TensorFlow coincide con las variables con los valores de management atravesando un gráfico dirigido con bordes con nombre, comenzando desde el objeto que se está cargando. Los nombres de borde generalmente provienen de nombres de atributos en objetos, por ejemplo, el "l1" en self.l1 = tf.keras.layers.Dense(5). tf.practice.Checkpoint usa sus nombres de argumentos de palabras clave, como en el "step" en tf.practice.Checkpoint(step=...).
El gráfico de dependencia del ejemplo anterior se ve así:


El optimizador está en rojo, las variables regulares están en azul y las variables de la ranura optimizador están en naranja. Los otros nodos, por ejemplo, representando el tf.practice.Checkpoint—As en negro.
Las variables de ranura son parte del estado del optimizador, pero se crean para una variable específica. Por ejemplo, el 'm' Los bordes anteriores corresponden al momento, que el Optimizer Adam rastrea para cada variable. Las variables de la ranura solo se guardan en un punto de management si la variable y el optimizador se guardarían, por lo tanto, los bordes discontinuos.
Vocación restore en tf.practice.Checkpoint cola de objetos Las restauraciones solicitadas, restaurando valores variables tan pronto como hay una ruta coincidente desde el Checkpoint objeto. Por ejemplo, puede cargar solo el sesgo del modelo que definió anteriormente reconstruyendo una ruta a través de la purple y la capa.
to_restore = tf.Variable(tf.zeros([5]))
print(to_restore.numpy()) # All zeros
fake_layer = tf.practice.Checkpoint(bias=to_restore)
fake_net = tf.practice.Checkpoint(l1=fake_layer)
new_root = tf.practice.Checkpoint(internet=fake_net)
standing = new_root.restore(tf.practice.latest_checkpoint('./tf_ckpts/'))
print(to_restore.numpy()) # This will get the restored worth.
El gráfico de dependencia para estos nuevos objetos es un subgrafio mucho más pequeño del punto de management más grande que escribió anteriormente. Incluye solo el sesgo y un mostrador de guardado que tf.practice.Checkpoint Usos para numerar los puntos de management.

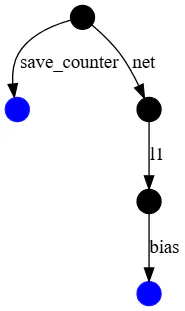
restore Devuelve un objeto de estado, que tiene afirmaciones opcionales. Todos los objetos creados en el nuevo Checkpoint han sido restaurados, entonces standing.assert_existing_objects_matched pases.
standing.assert_existing_objects_matched()
Hay muchos objetos en el punto de management que no han coincidido, incluido el núcleo de la capa y las variables del optimizador. standing.assert_consumed Solo pasa si el punto de management y el programa coinciden exactamente, y lanzaría una excepción aquí.
Restauraciones diferidas
Layer Los objetos en TensorFlow pueden diferir la creación de variables a su primera llamada, cuando las formas de entrada están disponibles. Por ejemplo, la forma de un Dense El núcleo de la capa depende tanto de las formas de entrada y salida de la capa, por lo que la forma de salida requerida como argumento del constructor no es suficiente información para crear la variable por sí solo. Desde que llamó a un Layer También lee el valor de la variable, debe ocurrir una restauración entre la creación de la variable y su primer uso.
Para apoyar este idioma, tf.practice.Checkpoint Defers restauraciones que aún no tienen una variable coincidente.
deferred_restore = tf.Variable(tf.zeros([1, 5]))
print(deferred_restore.numpy()) # Not restored; nonetheless zeros
fake_layer.kernel = deferred_restore
print(deferred_restore.numpy()) # Restored
Inspeccionar manualmente los puntos de management
tf.practice.load_checkpoint Devuelve un CheckpointReader Eso proporciona acceso de nivel inferior al contenido del punto de management. Contiene asignaciones de la clave de cada variable, a la forma y el dtype para cada variable en el punto de management. La clave de una variable es su ruta de objeto, como en los gráficos que se muestran arriba.
Nota: No hay una estructura de nivel superior en el punto de management. Solo saben las rutas y valores para las variables, y no tiene concepto de fashions, layers o cómo están conectados.
reader = tf.practice.load_checkpoint('./tf_ckpts/')
shape_from_key = reader.get_variable_to_shape_map()
dtype_from_key = reader.get_variable_to_dtype_map()
sorted(shape_from_key.keys())
Entonces, si está interesado en el valor de internet.l1.kernel Puede obtener el valor con el siguiente código:
key = 'internet/l1/kernel/.ATTRIBUTES/VARIABLE_VALUE'
print("Form:", shape_from_key[key])
print("Dtype:", dtype_from_key[key].title)
También proporciona un get_tensor Método que le permite inspeccionar el valor de una variable:
reader.get_tensor(key)
Seguimiento de objetos
Los puntos de management guardan y restauran los valores de tf.Variable Objetos “rastreando” cualquier objeto variable o rastreable establecido en uno de sus atributos. Al ejecutar un guardado, las variables se recursivamente de todos los objetos rastreados accesibles.
Como con las tareas de atributos directos como self.l1 = tf.keras.layers.Dense(5)asignar listas y diccionarios a los atributos rastreará sus contenidos.
save = tf.practice.Checkpoint()
save.listed = [tf.Variable(1.)]
save.listed.append(tf.Variable(2.))
save.mapped = {'one': save.listed[0]}
save.mapped['two'] = save.listed[1]
save_path = save.save('./tf_list_example')
restore = tf.practice.Checkpoint()
v2 = tf.Variable(0.)
assert 0. == v2.numpy() # Not restored but
restore.mapped = {'two': v2}
restore.restore(save_path)
assert 2. == v2.numpy()
Puede notar objetos de envoltura para listas y diccionarios. Estos envoltorios son versiones de management de las estructuras de datos subyacentes. Al igual que la carga basada en atributos, estos envoltorios restauran el valor de una variable tan pronto como se agrega al contenedor.
restore.listed = []
print(restore.listed) # ListWrapper([])
v1 = tf.Variable(0.)
restore.listed.append(v1) # Restores v1, from restore() within the earlier cell
assert 1. == v1.numpy()
Los objetos rastreables incluyen tf.practice.Checkpoint, tf.Module y sus subclases (por ejemplo keras.layers.Layer y keras.Mannequin), y contenedores de pitón reconocidos:
dict(ycollections.OrderedDict)recordtuple(ycollections.namedtuple,typing.NamedTuple)
Otros tipos de contenedores son no appropriateincluido:
collections.defaultdictset
Todos los demás objetos de Python son ignoradoincluido:
Resumen
Los objetos TensorFlow proporcionan un mecanismo automático fácil para guardar y restaurar los valores de las variables que usan.
Publicado originalmente en el









")


 de Daniel Caesar hace una apuesta desesperada por salvar una relación de falla")
{kind=link}