


Tabla de enlaces
Resumen y 1. Introducción
-
Fondo
2.1 Ethereum Primer
2.2 Verificación de dirección blanca
2.3 Análisis de mancha en contratos inteligentes y modelo de amenaza 2.4
-
Ejemplo y desafíos motivadores
3.1 Ejemplo motivador
3.2 Desafíos
3.3 Limitaciones de las herramientas existentes
-
Diseño de averificador y descripción de 4.1
4.2 Notaciones
4.3 Componente#1: Grapher de código
4.4 Componente#2: Simulador EVM
4.5 Componente#3: Detector de vulnerabilidad
-
Evaluación
5.1 Preguntas experimentales de configuración e investigación
5.2 RQ1: efectividad y eficiencia
5.3 RQ2: Características de los contratos vulnerables del mundo actual
5.4 RQ3: detección en tiempo actual
-
Discusión
6.1 amenazas a validez y limitaciones 6.2
6.3 Consideración ética
-
Trabajo relacionado
-
Conclusión, disponibilidad y referencias
5.2 RQ1: efectividad y eficiencia
5.2.1 Evaluación de resultados en Benchmark
Elaborando el punto de referencia. Después de recopilar de manera exhaustiva, informes técnicos de compañías de seguridad de Blockchain conocidas [12]hemos identificado seis contratos vulnerables confirmados, ya que P. Como todos sus archivos de código fuente disponibles, parcheamos manualmente a cada uno de ellos para componer P. Además, probamos manualmente cuatro contratos benignos de Defi ampliamente adoptado, es decir, aave [2]Compuesto [25]Préstamos parapace [69]y un protocolo de rendimiento [32]para formar el conjunto N. El motivo de la selección de estos cuatro contratos es doble. Por un lado, todos requieren la entrada de la dirección del contrato externo. Específicamente, AAVE y compuesto emplean principalmente tokens como garantía para

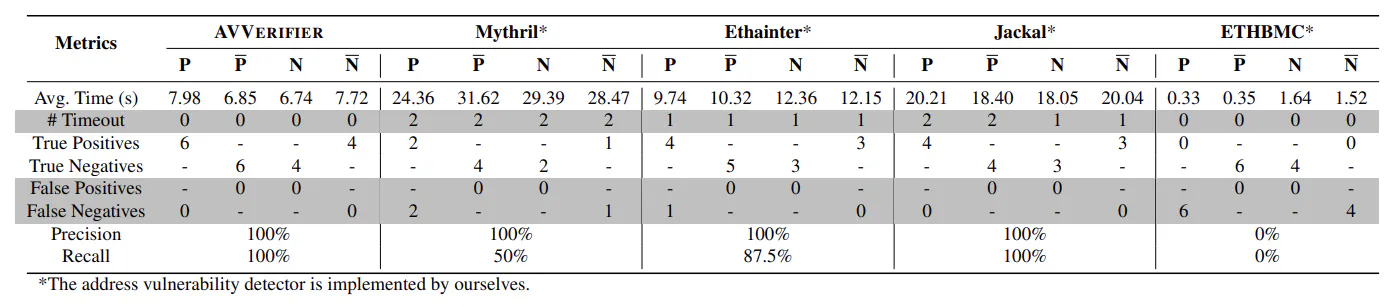
Pida prestada otro token valioso, mientras que Paraspace usa NFT como garantía. El protocolo de rendimiento utiliza la dirección de contrato externo de entrada para generar rendimiento colateral. Debido a que todos estos cuatro contratos realizan la verificación necesaria en la dirección aprobada, cumplen con P1 y P2. Por otro lado, después de ejecutar ciertas operaciones en cadena, los valiosos tokens en sus contratos se transfieren a la persona que llama, lo que plantea riesgos potenciales como P3. Del mismo modo, eliminamos deliberadamente su verificación en direcciones para que sean vulnerables, denotando este conjunto como N. En consecuencia, obtuvimos 20 casos de verdad de tierra. La Tabla 1 ilustra los resultados, donde las filas resaltadas se refieren a los resultados mal detectados.
Tiempo promedio. Se necesita un averificador alrededor de los 7.34s en promedio, mientras que Mythril se queda atrás considerablemente, tomando alrededor de 28.3s en promedio. Etherter y Jackal se sientan en el medio, con tiempos que van de 10.86 a 19.19s en promedio. El averificador es aproximadamente 3.86X, 1.48X y 2.61X más rápido que Mythril, Ethainter y Jackal, respectivamente. Al considerar los casos de tiempo de espera, tanto Avverifier como ETHBMC registraron cero, mientras que Mythril, Ethainter y Jackal encontraron un tiempo de espera en 8, 4 y 6 instancias, respectivamente. Además, podemos observar fácilmente que ETHBMC funciona bien en términos de ejecución del tiempo. Sin embargo, después de una auditoría y análisis de código integral en los registros de salida, creemos que se debe a que su enfoque de verificación de modelo limitado prioriza la eficiencia sobre la minuciosidad. En otras palabras, se pueden pasar por alto, lo que puede comprometer la precisión en escenarios complejos, como la vulnerabilidad de verificación de dirección centrada en este trabajo.
Precisión y retiro. La precisión y el recuerdo son dos métricas críticas para evaluar la efectividad de un analizador, donde el averificador supera a otras herramientas. Específicamente, Avverifier logra 100% de precisión y 100% de recuerdo en el punto de referencia. En el caso de Mythril y EthBMC, el problema principal son los falsos negativos. Para los casos que se pueden completar dentro del límite de tiempo, Mythril y EthBMC tienen una tasa negativa falsa del 50% y 100%, respectivamente. Especulamos que la razón principal de los resultados no ideales de EthBMC es doble. Por un lado, la estrategia de verificación de modelos limitadas de EthBMC se centra inherentemente en una gama específica de estados y caminos dentro de los contratos, potencialmente faltando las complejidades involucradas en la verificación de las direcciones debido a su alcance limitado. Por otro lado, ETHBMC requiere un estado inicial predefinido para el análisis. Sin embargo, es muy possible que este estado no sea óptimo para detectar la vulnerabilidad de verificación de direcciones, lo que potencialmente afecta su rendimiento. Etherter también tiene un peor rendimiento en comparación con el averificador en términos de retiro, con una tasa falsa negativa de alrededor del 12.5%. Creemos que el issue más crítico es la adopción de Gigahorse [36]una cadena de herramientas para el análisis binario. Según su implementación, una de sus limitaciones es su incapacidad para manejar perfectamente la memoria dinámica, lo que afecta el rendimiento de la ethinter en la identificación de funciones que usan ampliamente la memoria dinámica. En consecuencia, esta limitación conduce a los falsos negativos.
Causas raíz. Teniendo en cuenta las diferencias en las métricas al realizar análisis en el punto de referencia entre estas cinco herramientas, especulamos que hay cuatro razones para sus distinciones sobre el rendimiento en el punto de referencia. Primero, el averificador aprovecha completamente las características resumidas de P1. En el gráfico, filtra funciones sospechosas como candidatos, lo que cut back significativamente el número de estados posibles, una situación afecta estas herramientas. En segundo lugar, como se detalla en §4.4.4, la estrategia de investigación PathSe empleada por el simulador está específicamente diseñada para la vulnerabilidad de verificación de direcciones. Esta estrategia prioriza caminos que pueden conducir a vulnerabilidades. En tercer lugar, al manejar la memoria dinámica, las otras cuatro herramientas luchan para analizar con precisión funciones vulnerables que emplean ampliamente la asignación de memoria dinámica compleja. Por el contrario, el averificador aprovecha un simulador EVM, lo que le permite rastrear con precisión los parámetros de dirección sin modelar explícitamente comportamientos de memoria dinámica, mejorando así su capacidad para identificar tales funciones. Por último, el averificador adopta un enfoque de simulación directo, en lugar de una ejecución simbólica estática. Esta elección contribuye a su eficiencia. Estudios anteriores, como Klee [19]sugiera que los solucionadores SMT de backend pueden ser arrastrados significativos en el rendimiento.
5.2.2 Resultados de contratos del mundo actual
Para ilustrar aún más la efectividad del averificador en los contratos del mundo actual, realizamos el análisis en todos los contratos recolectados, 5,158,101 en whole. En consecuencia, 812 de ellos están marcados como vulnerables por el averificador. Para evaluar la efectividad del averificador, nuevamente usamos Mythril, Ethainter, Jackal y EthBMC como líneas de base. Sin embargo, porque la ONU


Leyabilidad del Bytecode, para una comparación más efectiva, tratamos de obtener su código fuente de Etherscan. Finalmente, recopilamos 369 piezas de código fuente. Los resultados finales de escaneo para todas estas cinco herramientas en 369 contratos de código abierto se muestran en la Tabla 2.
Tiempo promedio. Como podemos ver, para los 369 casos, Avverifier logra el segundo mejor rendimiento en términos de tiempo de análisis promedio. Además, no hay casos de tiempo de espera dentro del límite de 10 minutos. Ethainter está un lugar detrás, con 8.74 y 6 tiempos de espera. La eficiencia de Mythril se queda muy atrás, promediando 33.69s por caso y sufriendo 42 tiempos de espera superiores al umbral de 10 minutos, el más alto entre las herramientas comparadas. Jackal promedia alrededor de 29.96 con 60 tiempos de espera dentro. Finalmente, aunque ETHBMC tiene un tiempo promedio decente de 5.43S, sufre 164 casos de tiempo de espera, lo que afecta significativamente su efectividad. Al comparar la Tabla 2 y la Tabla 1, podemos observar que el rendimiento entre estas herramientas es más o menos consistente, excepto que ETHBMC tiene más casos de tiempo de espera en los casos del mundo actual. Especulamos que esto se debe a que necesita probar diferentes estados iniciales cuando el precise no puede explorar las rutas a las explotaciones, lo que lleva a un gran problema de eficiencia.
Precisión y retiro. Después de volver a ver manualmente todos estos contratos, el número de falsos positivos y falsos negativos también se muestra en la Tabla 2. Podemos observar fácilmente que hay 21 falsos positivos generados por Avverifier, lo que lleva a una precisión del 94.3%. La razón principal de esto es que hay métodos de verificación no convencionales en las direcciones. Excepto por los tres mecanismos que resumimos en §2.2, algunos de ellos delegan la verificación de abordados a otros contratos, que no es un método de verificación ampliamente adoptado. Además, algunos contratos realizan verificación a través de firmas digitales [17] o pruebas de merkle [50]. Actualmente, debido a problemas de eficiencia, el averificador no integra tales patrones. Además, ya que el análisis entre contracontratos es siempre un gran obstáculo para el análisis de contratos inteligentes [58]es un compromiso debe hacerse. En contraste, las otras cuatro líneas de base sufren problemas falsos negativos graves. Aunque Mythril emplea un enfoque de filtrado de ruta related al averificador, su retiro es solo 5.1%, porque la ejecución simbólica no puede encontrar de manera efectiva caminos factibles para explotar los contratos vulnerables. Etherer y Jackal, los cuales usan el marco Gigahorse, logran tasas de recuperación de solo 43.0% y 59.7%, respectivamente. Como mencionamos en §5.2.1, Gigahorse lucha por construir con precisión los CFG completos al manejar algunos contratos, que provienen de su manejo menos optimizado en la memoria dinámica. El retiro de ETHBMC es solo del 1.1%, cuya razón se debe principalmente a sus estados iniciales adoptados como declaramos anteriormente. Hemos realizado un estudio de caso para ilustrar cómo un caso está mal etiquetado como falso negativo por estas cuatro herramientas, consulte nuestro repositorio de código abierto en Hyperlink.


Autores:
(1) Tianle Solar, Universidad de Ciencia y Tecnología de Huazhong;
(2) Ningyu He, Universidad de Pekín;
(3) Jiang Xiao, Universidad de Ciencia y Tecnología de Huazhong;
(4) Yinliang Yue, Laboratorio Zhongguancun;
(5) Xiapu Luo, la Universidad Politécnica de Hong Kong;
(6) Haoyu Wang, Universidad de Ciencia y Tecnología de Huazhong.












{kind=link}