


Tabla de enlaces
Resumen y 1. Introducción
2. Método
3. Experimentos sobre datos reales
4. Ablaciones en datos sintéticos
5. ¿Por qué funciona? Algunas especulaciones
6. Trabajo relacionado
7. Conclusión, declaración de impacto, impacto ambiental, reconocimientos y referencias
A. Resultados adicionales sobre la decodificación autoespeculativa
B. Arquitecturas alternativas
C. velocidades de entrenamiento
D. Finetuning
E. Resultados adicionales en el comportamiento de escala del modelo
F. Detalles sobre CodeContests Finetuning
G. Resultados adicionales en puntos de referencia del lenguaje pure
H. Resultados adicionales sobre resumen de texto abstractivo
I. Resultados adicionales sobre razonamiento matemático en lenguaje pure
J. Resultados adicionales sobre el aprendizaje de inducción
Okay. Resultados adicionales sobre razonamiento algorítmico
L. Intuiciones adicionales sobre la predicción múltiple
M. Entrenamiento de hiperparámetros
B. Arquitecturas alternativas

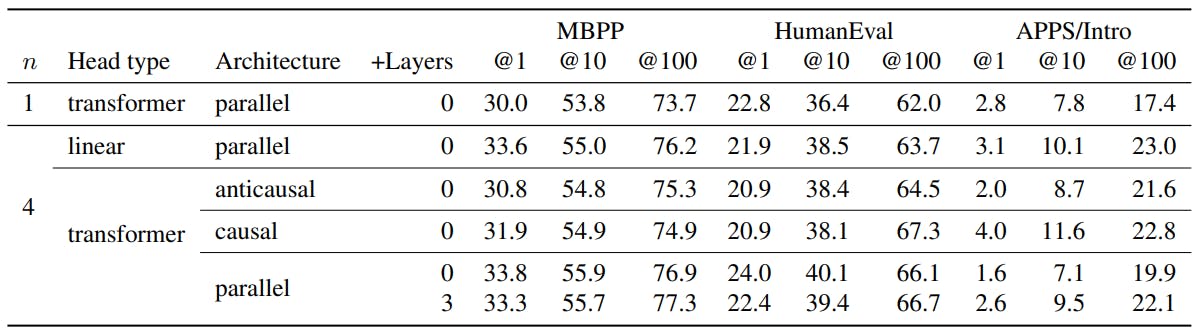
La arquitectura descrita en la Sección 2 no es la única opción sensata, sino que se demuestra técnicamente viable y bien realizada en nuestros experimentos. Describimos y comparamos arquitecturas alternativas en esta sección.
Sin embeddings replicados Replicar la matriz n Instances sin incrustación es un método easy para implementar arquitecturas de predicción de múltiples token. Sin embargo, requiere matrices con formas (D, NV) en la notación de la Sección 2, que es prohibitiva para los entrenamientos a gran escala.
Cabezales lineales Además de usar una sola capa de transformador para las cabezas hiotras arquitecturas son concebibles. Experimentamos con una sola capa lineal sin ninguna no linealidad como cabezas, que equivalen a sondeo lineal de la representación residual del modelo z. Las arquitecturas con más de una capa por cabeza también son posibles, pero no seguimos más esta dirección.



Autores:
(1) Fabian Gloeckle, justo en Meta, Cermics Ecole des Ponts Paristech y contribución igual;
(2) Badr Yoebi Idrissi, Honest at Meta, Lisn Université Paris-Saclayand y Contribución igual;
(3) Baptiste Rozière, justo en Meta;
(4) David López-Paz, feria en Meta y último autor;
(5) Gabriel Synnaeve, justo en Meta y un último autor.













{kind=link}