


Tabla de enlaces
Resumen y 1. Introducción
2. Método
3. Experimentos sobre datos reales
4. Ablaciones en datos sintéticos
5. ¿Por qué funciona? Algunas especulaciones
6. Trabajo relacionado
7. Conclusión, declaración de impacto, impacto ambiental, reconocimientos y referencias
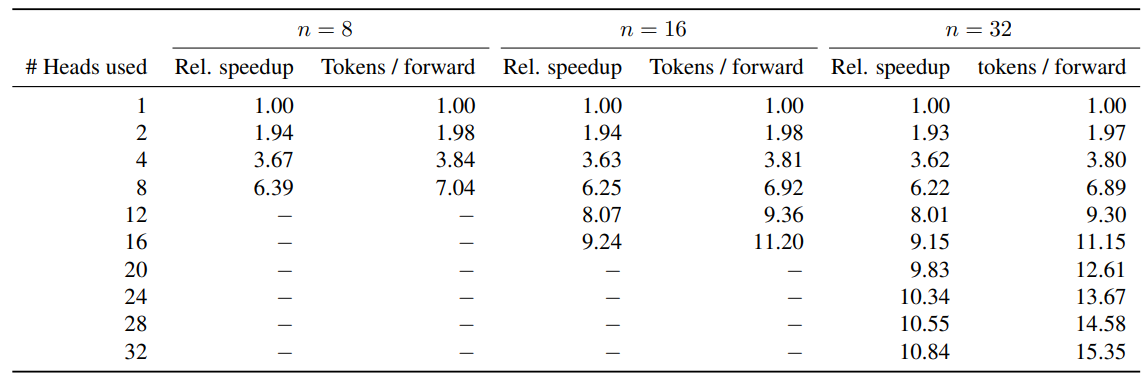
A. Resultados adicionales sobre la decodificación autoespeculativa
B. Arquitecturas alternativas
C. velocidades de entrenamiento
D. Finetuning
E. Resultados adicionales en el comportamiento de escala del modelo
F. Detalles sobre CodeContests Finetuning
G. Resultados adicionales en puntos de referencia del lenguaje pure
H. Resultados adicionales sobre resumen de texto abstractivo
I. Resultados adicionales sobre razonamiento matemático en lenguaje pure
J. Resultados adicionales sobre el aprendizaje de inducción
Ok. Resultados adicionales sobre razonamiento algorítmico
L. Intuiciones adicionales sobre la predicción múltiple
M. Entrenamiento de hiperparámetros
A. Resultados adicionales sobre la decodificación autoespeculativa

::: Data
Autores:
(1) Fabian Gloeckle, justo en Meta, Cermics Ecole des Ponts Paristech y contribución igual;
(2) Badr Yoebi Idrissi, Truthful at Meta, Lisn Université Paris-Saclayand y Contribución igual;
(3) Baptiste Rozière, justo en Meta;
(4) David López-Paz, feria en Meta y último autor;
(5) Gabriel Synnaeve, justo en Meta y un último autor.
:::
::: Información Este documento es Disponible en arxiv bajo CC por 4.0 licencia de escritura.
:::













{kind=link}